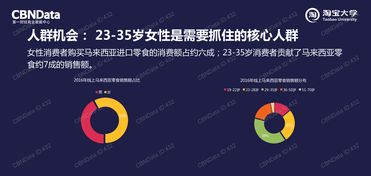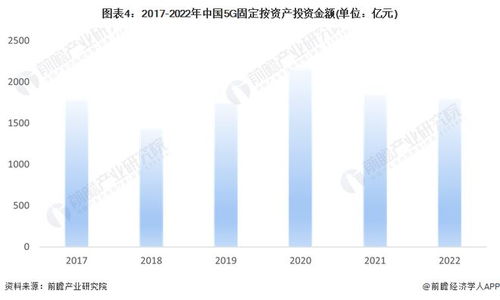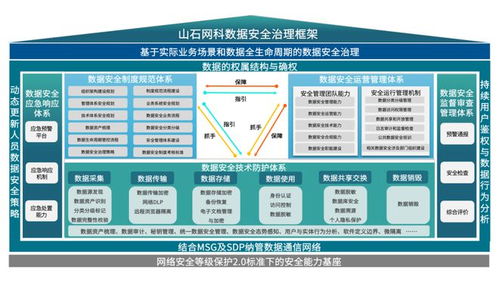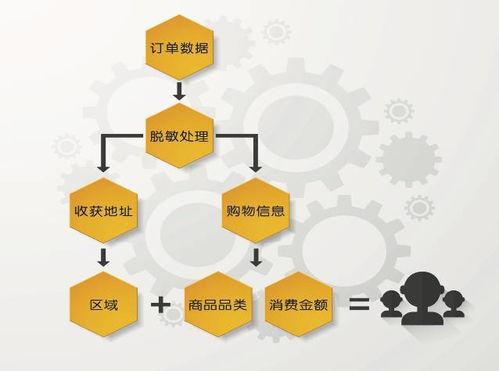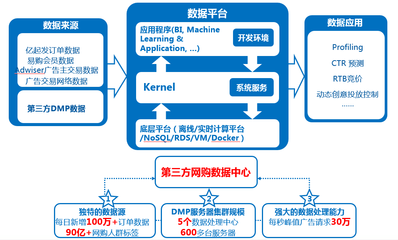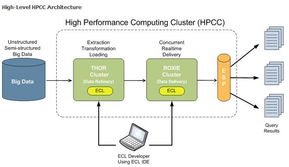
随着数字化转型的深入推进,大数据已成为驱动企业创新与决策的核心资源。在数据价值挖掘的道路上,数据处理服务正面临着三个日益突出的瓶颈:大容量、多格式和速度。这些挑战不仅考验着技术架构的弹性,更直接关系到数据能否被高效、准确地转化为商业洞察。
瓶颈一:大容量——数据洪流的存储与管理之困
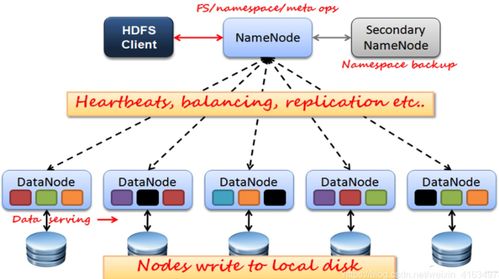
大数据的“大”首先体现在数据量上。从TB到PB,乃至EB级别,数据的快速增长超出了传统存储系统的处理极限。海量数据的存储不仅需要巨大的物理空间,更对数据的管理、备份、迁移和生命周期管理提出了严峻挑战。
应对策略:
1. 分布式存储架构:采用HDFS、对象存储等分布式系统,通过横向扩展来应对容量增长。
2. 数据分层与冷热分离:根据数据访问频率,将热数据、温数据、冷数据分别存储于高性能SSD、标准硬盘及低成本归档存储中,优化成本与性能。
3. 弹性伸缩的云服务:利用云存储的弹性特性,按需扩展容量,避免前期过度投资。
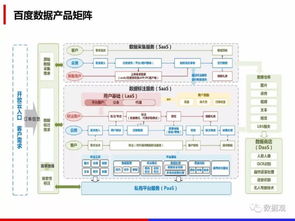
瓶颈二:多格式——异构数据的融合之难
大数据来源广泛,格式多样:既包括结构化的数据库记录,也涵盖半结构化的JSON、XML日志,以及非结构化的文本、图像、音视频等。这些异构数据格式不一、标准不同,导致数据整合、清洗和统一分析异常困难。
应对策略:
1. 统一数据湖架构:建立数据湖,以原始格式存储多源异构数据,再通过ETL或ELT流程按需转换。
2. 元数据管理与数据目录:通过统一的元数据管理,厘清数据血缘、格式定义与业务含义,提升数据可发现性与可用性。
3. 格式转换与标准化管道:利用Apache Parquet、ORC等列式存储格式进行高效压缩与序列化,平衡存储效率与查询性能。
瓶颈三:速度——实时处理与低延迟之需
在大数据应用中,速度瓶颈体现在两方面:一是批处理任务耗时过长,无法及时响应业务变化;二是对流式数据的实时处理能力不足,难以满足监控、预警等即时性场景。数据处理的速度直接决定了数据价值的“保鲜期”。
应对策略:
1. 批流一体处理框架:采用Apache Flink、Spark Structured Streaming等框架,在同一套系统中兼顾批量计算与流式计算。
2. 内存计算与缓存优化:利用Spark、Redis等内存计算技术,将热数据加载至内存,大幅提升处理效率。
3. 边缘计算与预处理:在数据产生源头进行过滤、聚合等预处理,减少传输与中心节点压力,降低端到端延迟。
数据处理服务的演进方向
面对三大瓶颈,现代数据处理服务正朝着“存算分离、弹性敏捷、智能自治”的方向演进。云原生数据平台、Serverless数据处理服务以及AI增强的数据管理工具,正在帮助企业构建更灵活、高效的数据处理体系。关键在于,企业需要根据自身业务特点,在数据规模、格式复杂度与处理时效之间找到平衡点,选择合适的技术栈与服务模式。
大容量、多格式与速度瓶颈是大数据发展过程中的必然挑战,但也是技术创新的催化剂。通过持续优化架构、引入先进工具与平台,并培养跨领域的数据工程能力,组织完全有能力将这些瓶颈转化为竞争优势,真正释放数据的巨大潜能。